Time estimate: You should be able to complete this tutorial in 60 to 90 minutes. Let’s go!
Step 0: Baseline (Starting Point)
Lakeside Mutual (LM) is a fictitious insurance company targeting the private market. The company provides several digital services to its customers and its employees. Three subdomains have been modeled, to be supported by applications:
- Customer Management
- Policy Management
- Risk Management
All application frontends and backends are developed and maintained by agile in-house teams at LM; application hosting and management are outsourced to a third party contractor.
Let us assume the following:
- LM has three backend systems for the management of customer master data, contracts, and insurance risk, modeled as bounded contexts and implemented in Java and JavaScript.
- To decompose these backend systems, the company has decided to realize a microservices architecture. The rationale for this strategic architectural decision is to be able to upgrade system parts more flexibly (in response to business change requests) and to be prepared for business growth (which is expected to increase workload, possibly turning the backends into bottlenecks requiring independent scaling).
- The frontend strategy is to use rich Web clients; hence, Single Page Applications (SPAs) are implemented in JavaScript.
One of the agile teams in corporate IT of LM has just been tasked with designing and developing a new customer self-service frontend. An early architectural spike (i.e., the Sprint 0) has unveiled that the required data is scattered across the three backend systems mentioned above (i.e., customer, policy, and risk management); none of these systems offers APIs well suited for the task yet (e.g., Web APIs or message queue endpoints).
The following analysis and design artifacts are available:
- A context map showing the system parts and their relationships as bounded contexts.
- User stories, accompanied by some Non-Functional Requirements (NFRs) regarding Quality Attributes (QAs).
- An informally sketched Architecture Overview Diagram (AOD).
Let us inspect these artifacts now as they provide valuable input to the API design.
Context map
A context map was created with Context Mapper, an open source project providing a Domain-Specific Language (DSL) for strategic Domain-Driven Design (DDD) and supporting tools. One of these tools turns a textual representation of the context map into UML (click here for the DSL source):
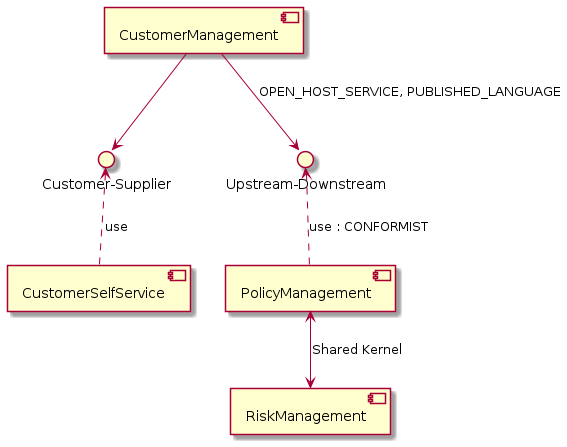
Note: Customer-Supplier, Upstream-Downstream OPEN_HOST_SERVICE, PUBLISHED_LANGUAGE, CONFORMIST are concepts/context relationship patterns from DDD. Their usage in Context Mapper is explained here.
User story and desired system qualities
The API and system under construction are supposed to support the following user story:
“As a customer of Lakeside Mutual, I would like to update my contact information myself online so that I can make sure that the data is entered correctly and I do not have to call an agent, which may involve long waiting times.”
Non-Functional Requirements (NFRs) regarding desired system qualities (e.g., performance, availability, maintainability) have been gathered in a Mini Quality Attribute Workshop (Mini-QAW) – informally, but still in a SMART way.
Two Non-Functional Requirements (NFRs) elicited during the Mini-QAW are:
- The user story about contact information update (see above) should not take longer than 2 seconds in 80% of the executions.
- LM expects 10.000 customers to use the new online service, 10% of which work with the system concurrently during office hours.
Architecture Overview Diagram (AOD)
The following informal diagram refines the context map from above by distinguishing application frontends and backends:
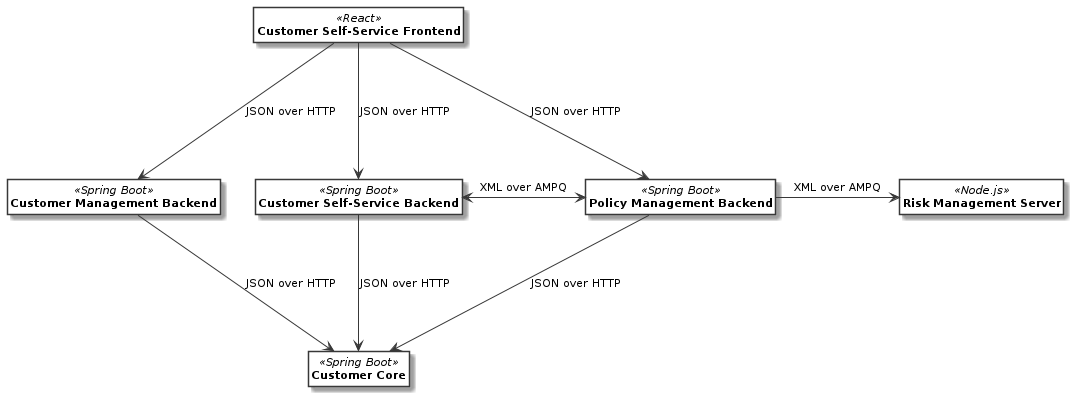
Note: Both diagrams represent the desired future system landscape; all shown systems are currently under construction or modernization.
Challenges (Tasks)
The customer self-service team has just taken the above user story off its backlog and included it in the current sprint. During a daily standup, the following activities have been identified by the team:
- Design a platform-independent API for the “upstream” Customer Management Backend, consumed by the “downstream” Customer Self-Service Frontend.1
- Specify the API endpoints (i.e., resources if we assume an HTTP-based Web API for now) and their operations (i.e., HTTP verbs/methods such as GET and POST), including request parameters and response structure (e.g., object structure of JSON payloads).
- Justify decisions based on the analysis and design artifacts listed/referenced above.
How can our Patterns for API Design, aka Microservice API Patterns (MAP), help the API designers at LM when dealing with these challenges? This question can be answered in the following five steps.
Step 1: Identification and Foundation Patterns
As a first step, it should be clarified which API(s) are required to realize the user story in the context of the already existing architecture and the NFRs.
Step 1.1: Domain/scenario analysis
Task: Perform a small event storming exercise for the user story outlined above, with the objective to identify events reporting status changes, commands triggering these events, and entities affected by them.
Hint: You may want to collect your findings in the form of a simple list of events, commands, and domain entities. These are the three core artifacts an event storming is supposed to produce/deliver. Since this is a simple scenario, two instances of each artifact type (e.g., events, commands, and entities) will suffice. Feel free to go further; the Context Mapper website provides links to introductory material and a full tutorial.
Solution (click to show)
In the first iteration, the following minimal setting of items can be identified and documented:
- Suited events are:
contact information entered and requested,contact information checked,contact information updated. - These events suggest commands:
enter contact information(address, phone number),check contact information,store contact information. - The domain entities produced and processed by these events and
commands are:
customer contact core data,address,phone number.
Step 1.2: API scoping
Task: Decide for one of the three “visibility” patterns (Public API, Community API, Solution-Internal API) and one of the two “integration type” patterns (Frontend Integration, Backend Integration) from the Foundation category.
Hints: You can find an overview of the Foundation category and links to the the pattern texts in the category overview.
Solution (click to show)
A Solution-Internal API is required, which supports Frontend Integration. The customer self-service application is a frontend, the customer management service a backend, both belonging to the same (sub-)domain and context. We could also see the API as a Community API if we anticipate that other services and frontends will require customer data later, but for now the team decided to focus only on a Solution-Internal API.
Step 1.3: Candidate endpoint list
Task: Turn the output of Steps 1 and 2 into a Candidate Endpoint List (CEL).
Hints: It has been decided to offer RESTful APIs earlier;
hence, endpoints correspond to resources identified by URIs and
operations correspond to HTTP verbs (methods) such as POST
and GET. A simple table like the following will
suffice:
| Endpoint | Operation | Data |
|---|---|---|
| … | … | … |
Solution (click to show)
A suited CEL looks like this:
| Endpoint | Operation | Data |
|---|---|---|
| Customer | Find (GET) | Returns list of customer identifiers |
| Read (GET) | in: CustomerId, out: Customer DTO | |
| Update (PUT) | in: (CustomerId, new address or phone number), out: (status code, link to updated customer resource) |
In this case, the CEL only contains one endpoint. Note that no “Create” operation (POST) is foreseen since the user story does not require such operation. Let’s assume that it is already supported by another backend service.
Step 2: Roles and Responsibilities (R)
Now that the scope and type of the API has been outlined, it is time to think about its architecture.
Step 2.1: Endpoint roles
Task: Select a role for all endpoints identified in Step 1.
Hint: You can find the pattern texts and an overview of the responsibility category in the responsibility category overview.
Solution (click to show)
The customer resource is an Information Holder Resource and, more precisely, a Master Data Holder because it has a long lifetime, data-oriented semantics, and many incoming references.
Step 2.2: Operation responsibilities
Task: Select a responsibility for all operations identified in Step 1.
Hint: The terms role and responsibility come from Responsibility-Driven Design (RDD): A role is a “set of related responsibilities” (here: API endpoint) and a responsibility is “an obligation to perform a task or know information” (here: operation).
Solution (click to show)
The GETters are Retrieval Operations as they access but do not change state data. The PUT is a State Creation Operation, with the change request being the event processed (resulting from the event storming in Step 1).
Step 2.3: Refine endpoint list
Task: Turn the CEL from Step 1 into a Refined Endpoint List by adding the role/responsibility patterns.
Hints: Also double check that the user story can actually be implemented this way; go back to an earlier step if needed to close a gap. Resist the temptation to design for future requirements to avoid analysis paralysis.
Solution (click to show)
The Refined Endpoint List may look like as follows:
| Endpoint | Role | Operation | Data/Entity | Responsibility |
|---|---|---|---|---|
| Customer | Master Data Holder | |||
| Find (GET) | Returns list of customer identifiers | Retrieval Operation | ||
| Read (GET) | in: CustomerId, out: Customer DTO | Retrieval Operation | ||
| Update (PUT) | in: (CustomerId, new address or phone number), out: (status information, link to updated customer resource) | State Creation Operation |
Note: If we want to express this preliminary high-level API design a bit more elaborately in a first API Description, we can specify it as follows:2
API description LakesideMutual
data type StatusInformation (D<bool>,L)
endpoint type CustomerManagement serves as INFORMATION_HOLDER_RESOURCE
exposes
operation findCustomer with responsibility RETRIEVAL_OPERATION
expecting payload D<void> // no payload
delivering payload "customerIDList":ID*
operation readCustomer with responsibility RETRIEVAL_OPERATION
expecting payload "customerID":ID
delivering payload "customerDTO":D?
operation updateCustomer with responsibility STATE_CREATION_OPERATION
expecting payload "customerDTO":D?
delivering payload StatusInformation
IPAStep 3: Basic and Composite Structures (S)
We now know what the API is supposed to support in terms of business capabilities and already have indicated the data transfer needs. Time to become more concrete!
Step 3.1 Message payload design
Task: Choose the Data Transfer Representations (DTRs) suited to implement the roles and responsibilities of the three API operations of the customer resource endpoint. More specifically, a) pick and combine one or more basic structure patterns (representation elements) and b) also pick an element stereotype.
Hints:
- You can find the pattern texts and an overview of the responsibility
category structure category overview.
Use the forces of the pattern texts as well as the NFRs to make informed
decisions.
- The element stereotypes are: Id Element, Data Element, Link Element, Metadata Element.
Solution (click to show)
Multiple solutions are possible:
- The
CustomerIdis an Id Element that can be transported as an Atomic Parameter. - The
CustomerDTOis a two-level Parameter Tree if we assume addresses and phone numbers to go to separate sub-elements. - The
StatusInformationis an Atomic Parameter List, combining a Metadata Element with a Link Element. You can also view it as an instance of an Error Report.
Step 3.2 Decision rationale
Task: Document your pattern selection decisions in one of the recognized notations for AD capturing, e.g., using a Y-statement or (M)ADR.
Solution (click to show)
A Y-statement capturing pattern selection decisions is:
“In the context of the customer self-service story, facing the need to guarantee a two-second response time, we decided for the patterns Atomic Parameter, Id Element (
CustomerId), Parameter Tree (CustomerDTO), Atomic Parameter List, Metadata Element, Link Element (StatusInformation) to achieve a good balance between message size and call frequency, accepting that this simple design will have to be refactored and enhanced once more stories have to be supported.”
Step 3.3 Service contract refinement (optional)
Task: Update the MDSL contract from above to express the data structures and pattern usage.
Solution (click to show)
The revised contract features the additional patterns to annotate and fully specify the representation elements:
API description LakesideMutual
data type Address {"country":D<string>,
("street":D<string>|"pobox":D<int>), "zip":D<int>, "city":D<string> }
data type PhoneNumber ("country":D<string>, "number":D<string>)
data type CustomerDTO <<Entity>> {
"id",
"name",
"addresses":Address*,
"phoneNumbers":PhoneNumber*}
data type StatusInformation
<<Annotated_Parameter_Collection>>(MD<bool>,L)
endpoint type CustomerManagementTake2
serves as INFORMATION_HOLDER_RESOURCE
exposes
operation findCustomer with responsibility RETRIEVAL_OPERATION
expecting payload D<void> // no payload
delivering payload customerIDList":ID<int>*
operation readCustomer with responsibility RETRIEVAL_OPERATION
expecting payload "customerIDList":ID<int>*
delivering payload CustomerDTO?
operation updateCustomer with responsibility EVENT_PROCESSOR
expecting payload CustomerDTO?
delivering payload StatusInformation
IPAStep 4: Quality Enhancements (Q)
Let us assume that the current design runs the risk of not meeting the NFRs stated under Step 0 (Baseline) above. In particular, the customer’s complete moving history with all addresses is returned by default. This information is not needed by the majority of API clients: however, the current design forces all of them to receive and process it. This wastes bandwidth and processing resources.
Step 4.1: Balancing message sizes
Task: Inspect the operation readCustomer in
CustomerManagementTake2. Find the patterns that discuss
inclusion/exclusion of referenced entity data. Decide how to switch from
the currently used design (i.e., the pattern used in the solution to the
previous steps) to a more suited one.
Hint 1: You can find the pattern texts and overviews in the quality category overview.
Hint 2: If the category overview pages turn out to be insufficient, you may want to try the cheat sheet; look for “My clients report performance problems” in the tables labeled with “Issue | Patterns to consider”.
Solution (click to show)
The first API design used an Embedded Entity for the customer to address relationship. According to the NFRs and the additional information from the beginning of this step, we have to refactor the API and introduce a dedicated address endpoint with its own operations which is then referenced via Linked Information Holders.
The API description changes to:
API description LakesideMutual
data type Address {"country":D<string>,
("street":D<string>|"pobox":D<int>), "zip":D<int>, "city":D<string> }
data type PhoneNumber ("country":D<string>, "number":D<string>)
data type CustomerDTO <<Entity>>
{"id", "name", "addresses":Address*, "phoneNumbers":PhoneNumber*}
data type RefactoredCustomerDTO <<Entity>> {"id", "name",
<<Linked_Information_Holder>>"addresses":L*, "phoneNumbers":PhoneNumber*}
data type StatusInformation <<Annotated_Parameter_Collection>>(MD<bool>,L)
endpoint type CustomerManagementTake3
serves as INFORMATION_HOLDER_RESOURCE
exposes
operation findCustomer with responsibility RETRIEVAL_OPERATION
expecting payload D<void> // no payload
delivering payload "customerIDList":ID<int>*
operation readCustomer with responsibility RETRIEVAL_OPERATION
expecting payload "customerIDList":ID<int>*
delivering payload RefactoredCustomerDTO?
operation readAddress with responsibility RETRIEVAL_OPERATION
expecting payload "addressId":L
delivering payload Address
operation updateCustomer with responsibility EVENT_PROCESSOR
expecting payload CustomerDTO?
delivering payload StatusInformation
IPAStep 4.2 Service implementation (optional)
Task: Implement the platform-independent design in the language and middleware of your choice, for instance, Java and Spring Boot (to be able to observe and measure the impact of the service design in runtime qualities).
Solution (click to show)
See public Lakeside Mutual repository.
Step 5: Evolution Patterns
The API design has now reached a sufficient level of elaboration so that it can be tried out with beta users.
Step 5.1: Selection of an (initial) Evolution strategy
Task: Which pattern describes how to make an initial release to get early feedback (“commitment-free API beta program testing”)?
Hints: You can find the pattern texts and an overview of the responsibility category here: evolution category overview.
Solution (click to show)
The pattern is Experimental Preview.
Step 5.2: Additional Evolution Patterns
Task: Which other evolution patterns would you decide for in the given project scenario (context, requirements)?
Solution (click to show)
The API operations exposed by this endpoints are mission-critical for many applications, so probably you will want to commit to a certain Limited Lifetime Guarantee or offer flexibility to upgrade by supporting at least Two in Production. To be able to communicate (in-)compatible changes, you will probably also decide to introduce Version Identifiers using the conventions known as Semantic Versioning.
Step 5.3 Service contract update
Task: Update the MDSL contract to reflect your decision from Step 5.1. Update your other analysis and design artifacts.
Hints: If you need some help with the MDSL syntax, you can find it here.
Solution (click to show)
MDSL can also express providers (as well as clients and gateways):
API provider LakesideMutualCorporateIT
offers CustomerManagementTake3
at endpoint location "Some URI address"
endpoint governance EXPERIMENTAL_PREVIEW
under conditions "Some Ts and Cs"
IPAEnd Result
Congratulations! Having completed Steps 1 to 5, you should now have produced the following artifacts:
- Updated analysis and design artifacts (e.g., updated context map and Y-statement or filled out MADR template)
- Candidate Endpoint List (CEL) and refined endpoint list
- MDSL snippets (on three levels of refinement/elaboration)
- (optionally) Swagger contract
- (optionally) LM sample implementation, testable with Postman or curl.
A more complete sample implementation of the LM scenario (that does not fully match the story and example used in this tutorial) is available in the public Lakeside Mutual repository.
Next: Self-Paced Exercise
You can find a similar, self-paced tutorial and repetition questions here.
Read this InfoQ article on strategic DDD for an explanation and examples of upstream/downstream.↩︎
In case you are wondering, the above notation is not pseudo-code but a specification that conforms to a formal language, a Microservice API-domain-specific language, as a mater of fact. This language is called Microservices Domain-Specific Language (MDSL), documented here. The endpoints and their operations form the service contract; the message representation elements are only sketched here, yielding an incomplete but still informative data contract. Patterns such as
INFORMATION_HOLDER_RESOURCEandRETRIEVAL_OPERATIONappear as role and responsibility stereotypes.*and?specify cardinalities.D<bool>represents a general data role with a boolean value.↩︎