Introduction to Microservices and APIs
Note that our API patterns book is less centered on microservices than this introduction.
Motivation
It is hard to escape the term microservices these days. Much has been said about this rather advanced approach to system decomposition since James Lewis’ and Martin Fowler’s early online post in April 2014. Early adopters’ experiences suggest that service design requires particular attention if microservices are supposed to deliver on their promises:
- How many service interfaces should be exposed in an API?
- Which service cuts let services and their clients deliver user value jointly, but couple them loosely?
- How often do services and their clients interact to exchange data? How much and which data should be exchanged?
- What are suitable message representation structures, and how do they change throughout service life cycles?
- How can the meaning of message representations be agreed upon – and how to stick to these contracts in the long run?
To address these and many other related design issues and choose working combinations from the many possible design options, application context and requirements must be known. Our Microservice API Patterns (MAP) cover and organize this solution space.
Our take on microservices
Let us recapitulate what microservices actually are (and where they came from).
Microservices architectures have evolved from previous incarnations of Service-Oriented Architectures (SOAs). They consist of independently deployable, scalable and changeable services, each having a single responsibility. These responsibilities model business capabilities. Microservices often are deployed in lightweight virtualization containers, encapsulate their own state, and communicate via message-based remote APIs in a loosely coupled fashion. Microservices solutions often leverage polyglot programming and polyglot persistence, and DevOps practices including decentralized continuous delivery and end-to-end monitoring (Zimmermann (2017)).
When it comes to protocol selection, message-based APIs, for instance
RESTful HTTP or queue-based event sourcing and streaming, have come to
dominate over remote procedure calls, including their object-oriented
variants. JSON is a particularly popular data serialization and message
exchange format.
API fundamentals
Our book defines APIs as this “A remote API is a set of well-documented network endpoints that allow internal and external application components to provide services to each other. These services help achieve domain-specific goals, for instance, fully or partially automating business processes. They allow clients to activate provider-side processing logic or support data exchanges and event notifications.”.
We also present an API domain model abstracting from protocol technology details.
What makes service and API design hard (and interesting)?
Microservices architectures include many remote APIs. The data representations exposed by these APIs must not only meet the information and processing needs of clients and other services, but also be designed and documented in an understandable and maintainable way.
While microservice API design and implementation might seem to be simple and straightforward from the distance, a closer look actually unveils that a lot of interesting problems are still waiting for API teams:
-
Requirements diversity: The wants and needs of API clients
differ from one another, and keep on changing. API providers have to
decide whether they want to offer good-enough compromises in a single
unified API or try to satisfy all client requirements
individually.
- Design mismatches: What backend systems can do (in terms of functional scope and quality), and how they are structured (in terms of endpoint and data definitions) , might be different from what clients expect. These differences have to be overcome.
- Goal conflicts (between API clients and API providers): For instance, the desire to innovate and market dynamics such as competing API providers trying to catch up on each other may cause more change and possibly incompatible evolution strategies than clients expect (and are able or willing to accept). Furthermore, publishing an API means giving up some control and thus limiting the freedom to change it. Any data exposed in an API can be used by the clients, sometimes in unexpected ways; when opening up internal systems, an API provider might lose its information advantage (e.g., over competition).
These conflicting requirements and stakeholder concerns must be balanced; many design trade-offs can be observed:
- Few calls that carry lots of data back and forth vs. many chatty, fine-grained interactions. Which choice is better in terms of performance, scalability, bandwidth consumption and evolvability?
- Stable, standardized, elaborate interfaces vs. fast changing, specialized, focused ones. How to find a balance between breadth and depth? How to keep the interfaces compatible without sacrificing their extensibility?
- Data consistency vs. reliability and fast response times. Should state changes be reported via API calls or event streaming? Should commands and queries be separated?
Existing design heuristics
You can find many excellent books providing deep advice about using RESTful HTTP, e.g., which verb or method to pick to implement a particular operation, or how to apply asynchronous messaging including routing, transformation, and guaranteed delivery. Allamaraju (2010) and Hohpe and Woolf (2003) are just two examples. Strategic Domain-Driven Design (Evans (2003), Vernon (2013)) can get you started with service identification. SOA, cloud and microservices infrastructure patterns are already taken care of, and structuring data storages also is understood well (think SQL, NoSQL).1
But how about structuring data exchanges? “Data on the outside” differs from “data on the inside”, to pick up P. Helland’s terminology. Data access/usage profiles drive many data modeling decisions, both for data on the inside and for data in the outside. However, there are also significant differences between inside and outside data in terms of their mutability, lifetime, accuracy, consistency and protection needs.
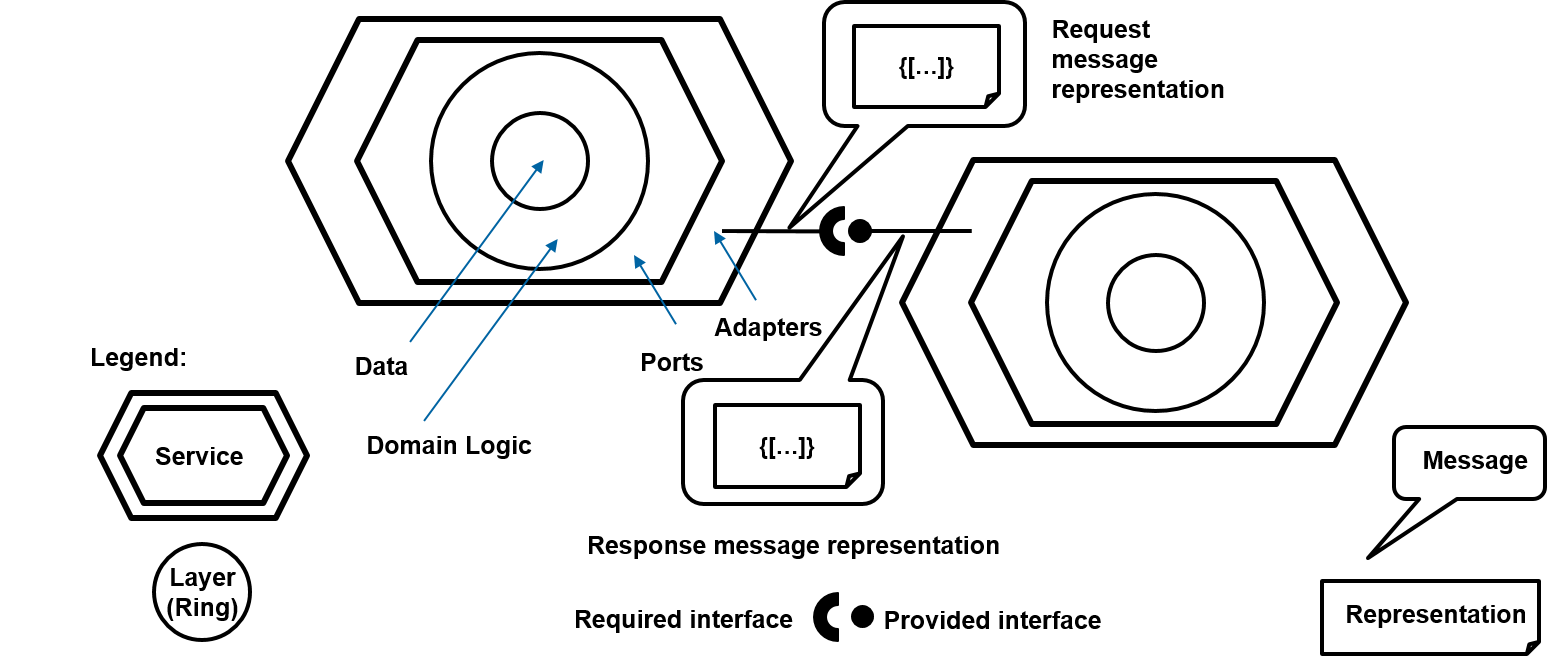
Our Microservice API Patterns (MAP)
Microservice API Patterns (MAP) takes a broad view on microservice API design and evolution, from the perspective of data on the outside – message representations and payloads exchanged when APIs are called. These messages are structured as representation elements which differ in their meaning as API endpoints and their operations have different architectural responsibilities. Also, critical design choices about the message structure and semantics strongly influence the design time and runtime qualities of an API and its underlying microservices implementations. Many options exist, with very different characteristics.
Patterns as knowledge sharing vehicles
Software patterns are sophisticated knowledge sharing vehicles with a
25-year track record.
We decided for the pattern format to share API design advice because:
- Pattern names aim at forming a domain vocabulary, an ubiquitous language. For instance, Gregor Hohpe’s and Booby Woolf’s Enterprise Integration Patterns have become the lingua franca of queue-based messaging; they were implemented in a number of frameworks and tools (see this installment of Insights).
- The forces and consequences sections of patterns support informed decision making, for instance about desired and achievable quality characteristics (but also downsides of certain designs).
- Patterns are soft around their edges: they only sketch solutions and do not provide blueprints to be followed blindly.
Patterns are not invented, but mined from practical experience and then curated and hardened via peer feedback, for instance received in writers’ workshops.2
Knowledge sources and categories
The patterns, their known uses and the examples have been mined from public Web APIs as well as application development and software integration projects the authors and their industry partners have been involved in.
Our pattern language addresses the following questions, which also define the pattern categories:
- The structure of messages and the message elements that play critical roles in the design of APIs. What is an adequate number of representation elements for request and response messages? How are these elements structured? How can they be grouped and annotated with supplemental usage information (metadata)?
- The impact of message content on the quality of the API. How can an API provider achieve a certain level of quality of the offered API, while at the same time using its available resources in a cost-effective way? How can the quality tradeoffs be communicated and accounted for?
- The roles and responsibilities of API operations. Which is the architectural role played by each API endpoint and its operations? How do these roles and the more detailed responsibilities impact microservice size and granularity?
- API descriptions as a means for API governance and evolution over time. How to deal with life cycle management concerns such as support periods and versioning? How to promote backward compatibility and communicate breaking changes?
Entry points and reading order
When maneuvering a complex design space to solve a wicked problem (and microservices design certainly qualifies as wicked), it is often hard to see the forest for the trees; it it not possible and not desired to serialize or standardize the problem solving activities. Therefore, our pattern language has multiple entry points such as a cheat sheet inspired by the one in the back matter of Patterns of Enterprise Application Architecture and various pattern filters such as patterns by quality and patterns by scope.
Each pattern text then can be seen as a small specialized article in its own,3 usually a few pages long and consisting of 2000 to 3000 words .4 These texts are structured according to a standard template. For instance, the template suggests to direct readers to the next patterns that become eligible and interesting once a particular one has been studied and applied. For instance, Embedded Entity suggests to add Linked Information Holders when relationships have to be followed on the client side, but the messages get too big if all referenced data is included. Pattern languages such as Enterprise Integration Patterns and Cloud Computing Patterns provide such “next” pointers too.
Our pattern template(s)
We use the following template for our patterns (in our papers and on this website): The context establishes preconditions for pattern applicability. The problem specifies a design issue to be resolved. The forces explain why the problem is hard to solve – architectural design issues and conflicting quality attributes are often referenced here; a non-solution may be pointed out as well. The solution answers the design question from the problem statement, describes how the solution works and which variants (if any) exist. It also gives an example and shares implementation hints. The consequences section discusses to which extent the solution resolves the pattern forces; it may also include additional pros and cons and identify alternative solutions. Known uses report real-world pattern applications. Finally, relations to other patterns are explained and additional pointers and references given under more information.
If you find the full pattern texts demanding or tiring to read, view them as reference information consulted on demand. On your first reading pass, try the following reading order, commonly applied in the patterns community:
- Problem, 2. Solution, 3. Known uses, 4. Context, 5. Forces, 6. Consequences
Note that in
the
book we use the following pattern structure:
When and Why to
Apply, How it Works, Discussion, Related Patterns, More Information.
Concluding Thoughts
Microservice API Patterns (MAP) is a volunteer project focused on the design and evolution of Microservice APIs addressing endpoint and message responsibility, structure, and quality. We hope you find the intermediate results of our ongoing efforts useful. We will be glad to hear about your feedback and constructive criticism. We also welcome contributions such as pointers to known uses or war stories in which you have seen some of the patterns (or variants of them) in action.
Most patterns featured on this site have been workshopped by the software patterns community and by experienced reviewers. They are applicable not only to microservice interfaces, but to any remote API leveraging plain text messages rather than stateful protocols or remote objects, synchronous ones using direct HTTP exchanges as well as asynchronous ones based on message queues. The captured knowledge already has been used as guidance for making architectural decisions in industry projects.
You might want to give our patterns a chance even if you have decided that microservices are not for you – for whatever reason: because they will go out of fashion soon, because they are not suited for you (microservices envy) or possibly suited, but the prerequisites cannot be met (microservices prerequisites), or because you suffer from buzzword fatigue caused by semantic diffusion – the design problems that recur when exposing remote APIs to distribute functionality will not go out of fashion any time soon!
If you made it here, you might want to check out our book.
References
See our related patterns page for reading recommendations.↩︎
Patterns by definition are supposed to stand the test of time, so you might be wondering whether it is feasible to mine patterns for a fast-moving, trending domain such as microservices. For instance, “SOA is dead; long live services” was published in January 2009, and the microservices term has been with us since 2014. So it is not clear if and/or when when we will get to see the first “microservices are dead” articles. Our risk mitigation strategy here is not to limit ourselves to microservices in the most narrow sense of the word, but write about proven design for message-based remote APIs (which do appear in microservices architectures, but not only there).↩︎
The Single Responsibility Principle not only applies to software designs, but also to pattern languages.↩︎
We yet have to succeed with our “pattern in a tweet” initiative (i.e., squeeze the essence of each pattern in a few bytes).↩︎